
MIT6.824 Lab2 - Raft
MIT6.824 Lab2 - Raft
写在前面
最终我还是决定写包括整个Lab2的总结而不是分成四个部分ABCD来写。其原因也很简单,在我写完2A的时候,我认为我的代码非常好用,然后我写了一篇总结,包括我的思路、代码结构这样的,相当志得意满。结果在写2B的时候,发现原来2A写的代码还是有不少bug的,2A的三个测试点并不能很好的测试出所有的corner case,能通过2A并不代表Leader Election部分的代码就完全没有问题。在辛苦debug完2B之后呢,我的与2A相关的代码已经修改了很多了,那篇2A的总结已经没有什么参考价值了。
后面果不其然,每写完一个部分,在之前认为”天衣无缝”的代码中总能找到不足之处和bug,所以,在完全写完这个Lab后,站在回归的角度再来写一个总结我认为是比较合理的。
我写这个Lab2,前后满打满算应该是花了十二天左右,因为是寒假,所以是几乎全天并且通宵高强度写这个Lab,看视频和论文两天 + Lab2A两天 + Lab2B四天 + Lab2C两天 + Lab2D三天。每次写完一个部分的Lab,我都得休息个两三天,看看《绝命毒师》放松一下,我的性格可能比较偏执,容易被bug一卡直接卡到通宵到第二天7点以后。所以每次做完Lab,晚上躺在床上都时不时要起身看看电脑上在跑的测试脚本,看到没有红色才能安心睡觉。 PS.附上做2C的时候床上拍的照片留念一下~

在写这个Lab之前,我从来没有写过golang,之前一直是一个Java-curd-noob,也没有什么多线程并发编程的经验,就在这个Lab中基本没有使用什么并发原语工具了,几乎都是Sleep个一段时间然后执行对应逻辑,也很少用到channel,全靠一个全局锁 XD。
一些建议
-
尽量少去网上找他人的代码来看
或者说主要借鉴一下代码结构就行,不要照着一个博客之类的猛抄,就像我上面说到的,作者可能写这个Part的时候觉得没啥问题,结果在后面就会导致错误。如果在debug的时候,需要对照一下,那也要仔细找找优质的博客,网上关于这个Lab的质量良莠不齐,有的人代码都写的一塌糊涂博客也发的很带劲…
关于debug,前两个part我十分推荐直接去看这个演示网站 https://raft.github.io/raftscope/index.html ,关于一些边界条件的判断,可以在这里找到正确的动画演示,它的正确性是值得信赖的,可以说是十分有用了!
还是推荐一个我认为质量非常高的博客:https://github.com/OneSizeFitsQuorum/MIT6.824-2021
-
多看论文,严格遵循Figure 2
我是学长推荐我论文也要看一遍下来再动工,确实,看完前5个Section再开始写代码,思路还是蛮清晰的,能够认识到下一步要做啥
-
学会使用助教提供的”符合人体工学”的日志工具
https://blog.josejg.com/debugging-pretty/ 他在他的网站上面已经讲得十分详细了,基本直接复制代码,装好环境就行。
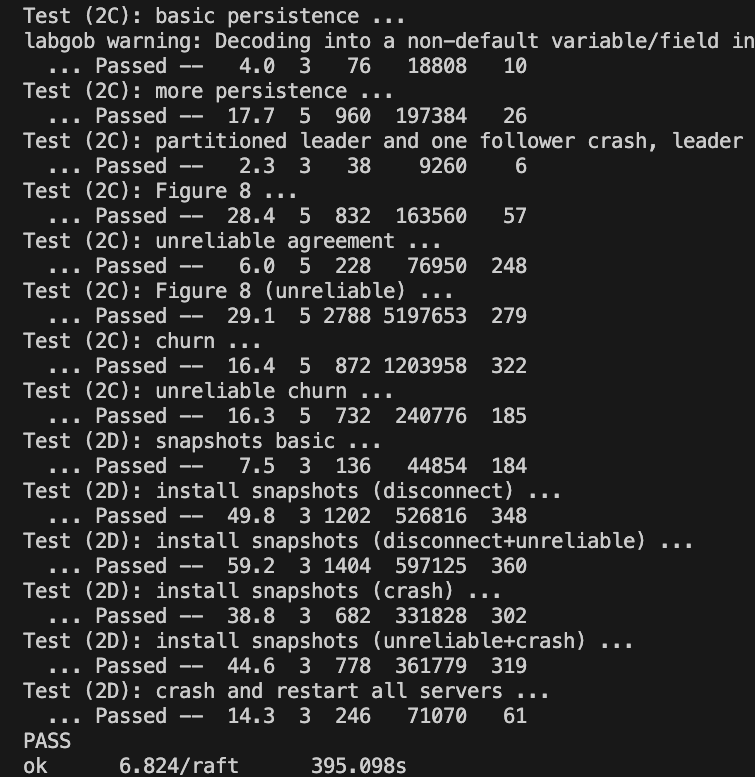
最后,放上我的四个部分合一的最终测试结果。
我的一轮测试需要花费7分多钟,其实在性能上是比较差劲的,主要表现在2D部分,比别人慢了很多,大概跟我用了很多Sleep有关吧,不过前后跑了百来趟都没出问题,我的Raft也算是相当稳固了。
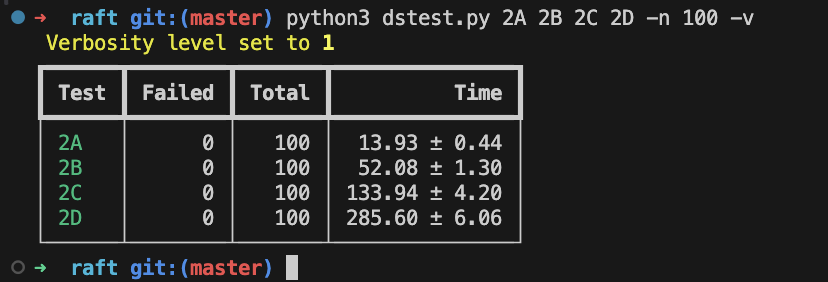
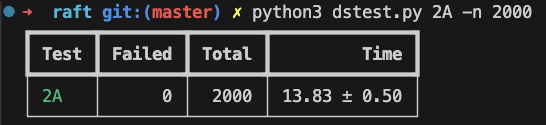
Lab2A-Leader Election
任务
-
完成RequestVote
-
完成不带日志的AppendEntries作为心跳检测。
-
完成ticker函数作为定时器,检测raft peer状态并作出对应操作如发起选举、发起心跳等
ticker
这个计时器部分感觉是2A中最需要考虑的部分了,我自己实现之后去网上看了好多其他人的实现方案,都各不相同,很难说谁的更好,我去看了etcd的源码,感觉有点复杂,加上我并不太熟练go的并发原语,很多看起来很优雅的操作也不太敢尝试,所以我在这部分的实现应该是不太好的,不过课的TA说不用太在意CPU的效率,我很多操作就能省则省了,程序就旨在好理解、好维护吧,效率应该是不太行的。
官方在代码注释中提到:
The easiest way to do this is to create a goroutine with a loop that calls time.Sleep();
Don’t use Go’s
time.Timerortime.Ticker, which are difficult to use correctly.
所以我就不打算使用那些复杂的倒计时器之类的东西了,看了看ticker函数中大概的结构,就是每隔一个比较小的时间tick,简单的判断一下各个指标是否超时,超时就执行对应的操作。每个tick间隔就直接让这个ticker线程Sleep过去就行,我直接设置的15秒作为一个tick的间隔。
- 如何判断是否超时?
我为了节省我大脑贫瘠的CPU算力,就用了我认为最好理解的一种方式了,即对于raft中三个超时分别维护两个变量,一个记录上次发生的时间,一个记录这次发生所拥有的时限timeout。
func (rf *Raft) ticker() {
for !rf.killed() {
rf.mu.Lock()
if rf.state == FollowerState {
if time.Since(rf.lastHeartbeaten) > rf.heartBeatenTimeout {
PrettyDebug(dTimer, "S%d's heartbeaten timeout, be candidate, Term:%d", rf.me, rf.currentTerm)
rf.state = CandidateState
}
}
if rf.state == CandidateState {
if time.Since(rf.lastElection) > rf.electionTimeout {
PrettyDebug(dTimer, "S%d's election timeout, raising an election, Term:%d", rf.me, rf.currentTerm)
go rf.raiseElection()
}
}
if rf.state == LeaderState {
if time.Since(rf.lastBroadcast) > rf.broadcastTimeout {
PrettyDebug(dTimer, "S%d's broadcast timeout, broadcasting for Term:%d", rf.me, rf.currentTerm)
go rf.raiseBroadcast(rf.currentTerm)
}
}
rf.mu.Unlock()
// sleep for a tick
tick := 15 * time.Millisecond
time.Sleep(tick)
}
}
// 一次选举的超时时间
// 只有在收到来自可以确认的Leader的心跳的时候才能刷新这个时长
func (rf *Raft) resetHeartbeatenTimeout() {
rf.lastHeartbeaten = time.Now()
rf.heartBeatenTimeout = time.Duration(rand.Intn(150)+300) * time.Millisecond
}
// 一次选举的超时时间
func (rf *Raft) resetElectionTimeout() {
rf.lastElection = time.Now()
rf.electionTimeout = time.Duration(rand.Intn(200)+300) * time.Millisecond
}
// 主动发起心跳的时间间隔
func (rf *Raft) resetBroadcastTimeout() time.Duration {
rf.broadcastTimeout = time.Duration(100) * time.Millisecond
return rf.broadcastTimeout
}
用我这种方法,时间区间就有一点要求了,在一次心跳超时的时间中,需要能够发送三次以上的心跳,才能比较稳定的通过测试。
RequestVote
就严格按照Figure 2即可,对于第二个点后半句话关于日志至少一样新的条件,在2A里面并不会检测到,因为涉及到log,2A里面并不需要log

有一点图中没有给出但在论文中有提到的是:
Current terms are exchanged whenever servers communicate;
if one server’s current term is smaller than the other’s, then it updates its current term to the larger value.
If a candidate or leader discovers that its term is out of date, it immediately reverts to follower state.
不管peer之间以什么方式交流,当发现有更高的Term,就需要更新自己的Term,更新完之后必定是Follower状态。所以不仅在心跳的时候要更新状态,requestVote也需要。
func (rf *Raft) RequestVote(args *RequestVoteArgs, reply *RequestVoteReply) {
// Your code here (2A, 2B).
// 2A
rf.mu.Lock()
defer rf.mu.Unlock()
if rf.killed() {
reply.Term = 0
reply.VoteGranted = false
return
}
reply.VoteGranted = false
reply.Term = rf.currentTerm
if args.Term < rf.currentTerm {
// just end
return
}
if args.Term > rf.currentTerm {
rf.updateTermPassively(args.Term)
}
reply.Term = rf.currentTerm
// never voted OR has voted to RPC's original peer
if rf.votedFor == -1 || rf.votedFor == args.CandidateId {
lastLogIndex, lastLogTerm := rf.getLastLogInfo()
if lastLogTerm < args.LastLogTerm ||
(lastLogTerm == args.LastLogTerm && lastLogIndex <= args.LastLogIndex) {
reply.VoteGranted = true
rf.votedFor = args.CandidateId
// heartbeaten only if voted for candidate
rf.state = FollowerState
rf.resetHeartbeatenTimeout()
rf.persist()
}
}
}
Raise Election
接收方上面已经基本做好了,接下来就是完成发送方,一般只有在发起选举的时候才会发送Request Vote,而只有当peer失去和Leader的心跳联系时,它应该认为已经没有Leader了,所以他就会成为一个Candidate,开始发起选举。
发起选举首先是对自己做一些update操作,大概就是
- 更新lastElection和electionTimeout
- currentTerm++
- change state to Candidate
- 给自己投票
- 给其他peer发RPC
这边有一个需要注意的地方,就是论文中提到的:
A candidate continues in this state until one of three things happens:
(a) it wins the election
(b) another server establishes itself as leader
(c) a period of time goes by with no winner
实际上我认为不需要做这么多判断
- 首先我们不需要做超时重试这个举动,因为超时之后ticker会检测到,自己重新发起一轮选举,在论文中提到发生split之后会
each candidate will time out and start a new election by incrementing its term and initiating another round of RequestVote RPCs.,所以超时重试是没有必要的,不需要自己来实现一个重试的操作。(至少我是没这么做) - 对于b条件,我认为没必要显式的检测它的发生,换个角度,当peer收到其他更高任期的RPC的时候(有很多可能,但如论文所说“whenever communicate”)需要回退到Follower状态,并且服从收到的高的任期Term。所以当这轮选举获胜之后,对当前状态做一个判断,判断自己是否还处于这次选举中
(term == currentTerm && state == Candidate)。如果check失败,说明这次选举已经因为某种原因结束或者失败了。
func (rf *Raft) raiseElection() {
rf.mu.Lock()
defer rf.mu.Unlock()
if rf.state == LeaderState {
return
}
rf.resetElectionTimeout()
rf.currentTerm++
rf.state = CandidateState
rf.votedFor = rf.me
rf.persist()
cnt := &Counter{
counter: 0,
mu: sync.Mutex{},
}
cnt.Increment()
need := len(rf.peers)/2 + 1
lastLogIndex, lastLogTerm := rf.getLastLogInfo()
args := &RequestVoteArgs{
Term: rf.currentTerm,
CandidateId: rf.me,
LastLogIndex: lastLogIndex,
LastLogTerm: lastLogTerm,
}
var once = sync.Once{}
// call each peer
for peer := range rf.peers {
if peer == rf.me {
continue
}
go rf.requestVoteHandler(cnt, args, peer, need, rf.me, &once)
}
}
func (rf *Raft) requestVoteHandler(cnt *Counter, args *RequestVoteArgs, peer int, need int, me int, once *sync.Once) {
reply := &RequestVoteReply{}
ok := rf.sendRequestVote(peer, args, reply)
if ok {
rf.mu.Lock()
if reply.VoteGranted {
// It should have happened only once?
if cnt.IncrementAndGet() >= need {
once.Do(func() {
// become leader
if rf.state == CandidateState && rf.currentTerm == args.Term {
rf.state = LeaderState
// 2B: initializeLogs when being leader
lastLogIndex, _ := rf.getLastLogInfo()
for peer := range rf.peers {
rf.nextIndex[peer] = lastLogIndex + 1
rf.matchIndex[peer] = 0
}
go rf.raiseBroadcast(rf.currentTerm)
}
})
}
}
if reply.Term > args.Term {
PrettyDebug(dVote, "S%d receive higher term(%d > %d) from S%d", me, reply.Term, args.Term, peer)
if rf.state == CandidateState && rf.currentTerm == args.Term {
rf.updateTermPassively(reply.Term)
cnt.Clear()
}
}
rf.mu.Unlock()
}
}
Append Entries
在2A中,这个RPC只需要完成很简单的判断就行,就是把它当成一个心跳而已,这边是需要在成为Leader的第一时间发送AE的,才能保证很快的选出Leader。
逻辑简单,记得刷新heartbeat时间相关数据就行。遇到什么问题就再好好看看Figure 2就行。
2A测试详解
第一个测试叫initial election,三个raft,检查初始化选举,保证只有一个领导,同时选举成功后一段时间不会触发新选举,总而言之是测试raft稳态
第二个测试叫election after network failure,三个raft,会先后分别测试领导挂机、旧领导恢复上线、一个领导和一个马仔挂机、马仔恢复上线、旧领导恢复上线,总而言之是测试回合值更新和判断和选举策略
第三个测试叫multiple elections,七个raft,九次迭代,每次迭代都会随机选三个raft挂机,然后再让挂机的raft恢复连接,保证过程中最多一个领导
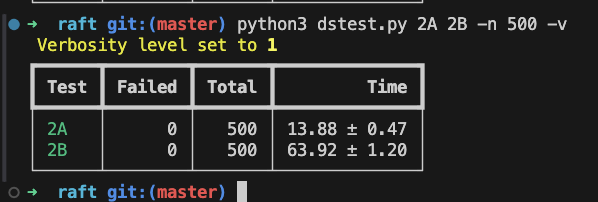
Lab2B-Log Replicated
2B比较难,bug也会比较多,不能着急,慢慢调~
一步一步写吧
AppendEntries RPC
func (rf *Raft) AppendEntries(args *AppendEntriesArgs, reply *AppendEntriesReply) {
rf.mu.Lock()
defer rf.mu.Unlock()
reply.Term = rf.currentTerm
reply.Success = false
// 1. Reply false if term < currentTerm
if args.Term < rf.currentTerm {
return
}
// 选举的时候发现已经有Leader,此时可能是竞争选举,认为自己失败,退回Follower
if args.Term == rf.currentTerm && rf.state == CandidateState {
rf.updateTermPassively(rf.currentTerm)
}
if args.Term > rf.currentTerm {
rf.updateTermPassively(args.Term)
rf.leaderId = args.LeaderId
}
// 此时可以确认对方是可以确认的Leader,刷新
rf.resetHeartbeatenTimeout()
// 2B
reply.Term = rf.currentTerm
lastLogIndex, _ := rf.getLastLogInfo()
if args.PrevLogIndex < rf.lastIncludedIndex {
reply.Success = false
reply.XTerm = -1
reply.XLen = lastLogIndex
return
}
// 2. Reply false if log doesn’t contain an entry at prevLogIndex whose term matches prevLogTerm
// 先匹配上相交点
if args.PrevLogIndex > lastLogIndex {
reply.XLen = lastLogIndex
reply.XTerm = -1
return
}
var matchingTerm int
if args.PrevLogIndex == rf.lastIncludedIndex {
matchingTerm = rf.lastIncludedTerm
} else {
matchingTerm = rf.getLog(args.PrevLogIndex).Term
}
if matchingTerm != args.PrevLogTerm && args.PrevLogTerm != 0 {
reply.XLen = lastLogIndex
reply.XTerm = matchingTerm
reply.XIndex, _ = rf.getLogIndexesWithTerm(reply.XTerm)
return
}
reply.Success = true
// prev log check pass, recognize each's logs before previndex are consist
// 从PrevLogIndex开始,找出自己的日志中与Leader对应位置处不一致的日志,将此日志后续的所有日志删除,并将新的日志添加到后面
for i, entry := range args.Entries {
idx := args.PrevLogIndex + i + 1
lastLogIndex, _ = rf.getLastLogInfo()
if idx == lastLogIndex+1 {
// 4. Append any new entries not already in the log
rf.logs = append(rf.logs, entry)
}
if rf.getLog(idx).Term != entry.Term {
// 3. If an existing entry conflicts with a new one (same index but different terms),
// delete the existing entry and all that follow it
rf.logs = rf.copyLogs(rf.lastIncludedIndex+1, idx)
// 4. Append any new entries not already in the log
rf.logs = append(rf.logs, args.Entries[i:]...)
break
}
}
// 5. If leaderCommit > commitIndex, set commitIndex = min(leaderCommit, index of last new entry)
if args.LeaderCommit > rf.commitIndex {
rf.commitIndex = min(args.LeaderCommit, args.PrevLogIndex+len(args.Entries))
}
rf.persist()
}
一个值得注意的地方,也是我在2D才发现的,也可能只有我会犯这种毛病。就是在填写reply的Term的时候,如果发现被动的UpdateTerm了,要把这个Term更新到reply中,我之前一直没做这一步,到了2D才发现的,导致了迟迟无法达成一致。
发送方 Leader逻辑处理
func (rf *Raft) appendEntriesHandler(peer int, term int, args *AppendEntriesArgs) {
reply := &AppendEntriesReply{}
ok := rf.sendAppendEntries(peer, args, reply)
if !ok {
return
}
rf.mu.Lock()
defer rf.mu.Unlock()
if rf.state != LeaderState {
return
}
if reply.Term < rf.currentTerm {
return
}
if reply.Term > rf.currentTerm {
rf.updateTermPassively(reply.Term)
return
}
// reply.Term == currentTerm
if reply.Success {
// Eventually nextIndex will reach a point where the leader and follower logs match.
// the follower’s log is consistent with the leader’s
peerNextIndex := args.PrevLogIndex + len(args.Entries) + 1
peerMatchIndex := args.PrevLogIndex + len(args.Entries)
rf.nextIndex[peer] = max(rf.nextIndex[peer], peerNextIndex)
rf.matchIndex[peer] = max(rf.matchIndex[peer], peerMatchIndex)
// update leader's commitIndex
// by calculate the index of majority could keep up with
sortedMatchIndex := make([]int, 0)
lastLogIndex, _ := rf.getLastLogInfo()
sortedMatchIndex = append(sortedMatchIndex, lastLogIndex)
for i := 0; i < len(rf.peers); i++ {
if i == rf.me {
continue
}
sortedMatchIndex = append(sortedMatchIndex, rf.matchIndex[i])
}
sort.Ints(sortedMatchIndex)
newCommitIndex := sortedMatchIndex[len(rf.peers)/2]
if newCommitIndex >= rf.commitIndex && rf.getLog(newCommitIndex).Term == rf.currentTerm {
rf.commitIndex = newCommitIndex
}
} else {
// 2C optimize log catch up
if reply.XTerm == -1 {
rf.nextIndex[peer] = reply.XLen + 1
} else {
_, lastIndex := rf.getLogIndexesWithTerm(reply.XTerm)
if lastIndex == -1 {
// 没有这个term的
rf.nextIndex[peer] = reply.XIndex
} else if lastIndex > 0 {
rf.nextIndex[peer] = lastIndex
}
}
if rf.nextIndex[peer] > 1 {
rf.nextIndex[peer]--
}
}
}
统一发送AppendEntries给所有peer
func (rf *Raft) raiseBroadcast(term int) {
rf.mu.Lock()
defer rf.mu.Unlock()
if term != rf.currentTerm {
return
}
if rf.state != LeaderState {
return
}
for peer := range rf.peers {
if peer == rf.me {
continue
}
preLogIndex := rf.nextIndex[peer] - 1
lastLogIndex, _ := rf.getLastLogInfo()
if preLogIndex < rf.lastIncludedIndex { // peer落后太多了,已经在snapshot里了,只能直接发动installSnapshot了
args := &InstallSnapshotArgs{
Term: rf.currentTerm,
LeaderId: rf.me,
LastIncludedIndex: rf.lastIncludedIndex,
LastIncludedTerm: rf.lastIncludedTerm,
Data: rf.persister.snapshot,
}
go rf.installSnapshotHandler(args, peer)
} else {
args := &AppendEntriesArgs{
Term: term,
LeaderId: rf.me,
PrevLogIndex: preLogIndex,
PrevLogTerm: rf.getLog(preLogIndex).Term,
LeaderCommit: rf.commitIndex,
Entries: rf.getLogs(preLogIndex+1, lastLogIndex+1),
}
go rf.appendEntriesHandler(peer, term, args)
}
}
rf.lastBroadcast = time.Now()
rf.resetBroadcastTimeout()
}
Apply Log
这一步的意思是把达成共识的Log,发送到状态机中。
func (rf *Raft) applyLogHandler(applyCh chan ApplyMsg) {
for !rf.killed() {
time.Sleep(10 * time.Millisecond)
appliedMsgs := []ApplyMsg{}
rf.mu.Lock()
for rf.commitIndex > rf.lastApplied {
rf.lastApplied++
if rf.lastApplied <= rf.lastIncludedIndex {
continue
}
applied := ApplyMsg{
CommandValid: true,
Command: rf.getLog(rf.lastApplied).Command,
CommandIndex: rf.lastApplied,
}
appliedMsgs = append(appliedMsgs, applied)
}
rf.mu.Unlock()
for _, msg := range appliedMsgs {
applyCh <- msg
}
}
}
一个注意的点就是不要在锁里面发东西到Channel里,会有一些阻塞的问题。
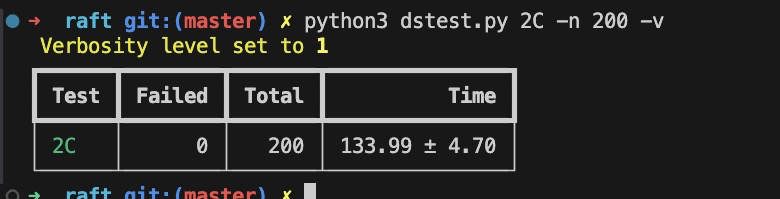
Lab2C-Persistence
最简单的一集,做好持久化就行
func (rf *Raft) persist() {
// Your code here (2C).
PrettyDebug(dPersist, "S%d Saving persistent state to stable storage at Term:%d.", rf.me, rf.currentTerm)
w := new(bytes.Buffer)
e := labgob.NewEncoder(w)
e.Encode(rf.currentTerm)
e.Encode(rf.votedFor)
e.Encode(rf.logs)
e.Encode(rf.lastIncludedIndex)
e.Encode(rf.lastIncludedTerm)
data := w.Bytes()
rf.persister.SaveRaftState(data)
}
// restore previously persisted state.
func (rf *Raft) readPersist(data []byte) {
if data == nil || len(data) < 1 { // bootstrap without any state?
return
}
// Your code here (2C).
PrettyDebug(dPersist, "S%d Restoring previously persisted state at Term:%d.", rf.me, rf.currentTerm)
r := bytes.NewBuffer(data)
d := labgob.NewDecoder(r)
rf.mu.Lock()
defer rf.mu.Unlock()
d.Decode(&rf.currentTerm)
d.Decode(&rf.votedFor)
d.Decode(&rf.logs)
d.Decode(&rf.lastIncludedIndex)
d.Decode(&rf.lastIncludedTerm)
}
有个点,就是在Raft的Make函数里面,不仅要ReadPersistence,还要恢复一下nextIndex[]的状态。
// 2C
// initialize from state persisted before a crash
rf.readPersist(persister.ReadRaftState())
lastLogIndex, _ := rf.getLastLogInfo()
for peer := range rf.peers {
rf.nextIndex[peer] = lastLogIndex + 1
}
Lab2D-Snapshot
日志快速追赶
加入日志压缩功能后,需要注意及时对内存中的 entries 数组进行清除。即使得废弃的 entries 切片能够被正常 gc,从而避免内存释放不掉并最终 OOM 的现象出现。
可以参考上面的代码,就是在AppendEntries相关的部分。
这边最难受的就是,需要对LogEntry[]做一个包装的操作,我之前没有做,访问指定Index的Log,就只是去切片里面直接访问,后面需要对整体代码做重构,期间出了好多好多好多好多好多的Bug T_T
Entry相关
这边感觉写的真的很烂,但是能跑就是了,能写好还是要写好的,能少很多bug。
type Entry struct {
Term int
Command interface{}
}
// index = lastIncludedIndex + index
func (rf *Raft) getLog(index int) *Entry {
i := index - rf.lastIncludedIndex
return &rf.logs[i]
}
func (rf *Raft) getLogs(startIndex, endIndex int) []Entry {
slice := []Entry(nil)
for i := startIndex; i < endIndex; i++ {
slice = append(slice, rf.logs[i-rf.lastIncludedIndex])
}
return slice
}
func (rf *Raft) copyLogs(startIndex, endIndex int) []Entry {
slice := []Entry(nil)
slice = append(slice, Entry{0, nil})
for i := startIndex; i < endIndex; i++ {
slice = append(slice, rf.logs[i-rf.lastIncludedIndex])
}
return slice
}
// Need Lock
// return last's index and term
// index = 0 means no logs
func (rf *Raft) getLastLogInfo() (index int, term int) {
if len(rf.logs) <= 1 {
return rf.lastIncludedIndex, rf.lastIncludedTerm
}
lastLogIndex := len(rf.logs) - 1 + rf.lastIncludedIndex
lastLogTerm := rf.logs[len(rf.logs)-1].Term
return lastLogIndex, lastLogTerm
}
func (rf *Raft) getLogIndexesWithTerm(term int) (firstIdx, lastIdx int) {
if term == 0 {
return 0, 0
}
first, last := math.MaxInt, -1
if rf.lastIncludedTerm == term {
first = min(first, rf.lastIncludedIndex)
last = max(last, rf.lastIncludedIndex)
}
for i := 1; i < len(rf.logs); i++ {
if rf.logs[i].Term == term {
first = min(first, i+rf.lastIncludedIndex)
last = max(last, i+rf.lastIncludedIndex)
}
}
if last == -1 {
return -1, -1
}
return first, last
}
Snapshot
func (rf *Raft) Snapshot(index int, snapshot []byte) {
// Your code here (2D).
rf.mu.Lock()
defer rf.mu.Unlock()
lastLogIndex, _ := rf.getLastLogInfo()
if rf.lastIncludedIndex >= index {
return
}
rf.lastIncludedTerm = rf.getLog(index).Term
rf.logs = rf.copyLogs(index+1, lastLogIndex+1)
rf.lastIncludedIndex = index
rf.persistAndSnapshot(snapshot)
}
Install Snapshot RPC
func (rf *Raft) InstallSnapshot(args *InstallSnapshotArgs, reply *InstallSnapshotReply) {
rf.mu.Lock()
defer rf.mu.Unlock()
if args.Term < rf.currentTerm {
reply.Term = rf.currentTerm
return
}
if args.Term > rf.currentTerm {
rf.updateTermPassively(args.Term)
}
reply.Term = rf.currentTerm
rf.resetHeartbeatenTimeout()
if rf.commitIndex >= args.LastIncludedIndex {
return
}
// 将快照后的logs切割,快照前的直接applied
index := args.LastIncludedIndex
tempLogs := make([]Entry, 0)
tempLogs = append(tempLogs, Entry{0, nil})
lastLogIndex, _ := rf.getLastLogInfo()
if index < lastLogIndex {
// 快照并不能包含接收者的所有的日志条目
// 把快照包含的条目都裁剪掉,留下快照不包含的
tempLogs = append(tempLogs, rf.getLogs(index+1, lastLogIndex+1)...)
}
rf.lastIncludedIndex = index
rf.lastIncludedTerm = args.LastIncludedTerm
rf.logs = tempLogs
rf.lastApplied = rf.lastIncludedIndex
rf.commitIndex = rf.lastIncludedIndex
rf.persistAndSnapshot(args.Data)
msg := ApplyMsg{
SnapshotValid: true,
Snapshot: args.Data,
SnapshotTerm: rf.lastIncludedTerm,
SnapshotIndex: rf.lastIncludedIndex,
}
go func(msg ApplyMsg) {
rf.applyChannel <- msg
}(msg)
}
Handler
func (rf *Raft) installSnapshotHandler(args *InstallSnapshotArgs, peer int) {
reply := &InstallSnapshotReply{}
ok := rf.sendInstallSnapshot(peer, args, reply)
if ok {
rf.mu.Lock()
defer rf.mu.Unlock()
if rf.currentTerm != args.Term {
return
}
if rf.currentTerm < reply.Term {
rf.updateTermPassively(reply.Term)
return
}
rf.matchIndex[peer] = max(args.LastIncludedIndex, rf.matchIndex[peer])
rf.nextIndex[peer] = max(args.LastIncludedIndex+1, rf.nextIndex[peer])
}
}
func (rf *Raft) CondInstallSnapshot(lastIncludedTerm int, lastIncludedIndex int, snapshot []byte) bool {
return true
}
在2022的版本中,Lab官方已经不推荐实现CondInstallSnapshot了,只要简单返回true即可。
2024-02-14
就先这样吧,后面有时间再补充了。
把Lab2写完,确实感觉收获不少,但是已经2月中旬了,马上也要开始准备三月份的面试了,算法也没刷多少,八股也没准备,感慨自己醒悟太晚,大一大二浪费了很多时间,心里还是很迷茫的。希望能好运吧。
补充
幽灵复现问题
大概就是下面图片表示的,可能在某些场景下长时间无法提供正确的读服务。如果你有仔细观察过raft运行的时候的日志,就能发现这个问题了。
大概描述起来就是,Leader在一个高的Term时有很多低Term的Log还没有被commit,因为raft不允许这个操作。

一个解决方法就是在Leader当选的时候记录一条no-op的日志,让之前的Log都被commit,使读服务快速恢复正常。
if rf.state == CandidateState && rf.currentTerm == args.Term {
rf.state = LeaderState
rf.logs = append(rf.logs, Entry{rf.currentTerm, 0})
}
比如这样,并且这样也确实很大提升了我Lab2D的执行效率,减少了将近100s的测试时长!不过我的Lab2B全挂了,应该是官方还没有考虑这个情况吧,大佬的博客中也是这么认为的。所以我就把2B里面校验Index的所有assert都注释掉了哈哈哈
原本是需要470-490s的,现在舒服多啦!
Bug-report - Lab3B丢失消息
在Lab3的TestSnapshotUnreliableRecoverConcurrentPartition3B测试中总是存在丢失消息的问题,这个问题似乎全网只有我会出现,这是由于我的log实现方式不够理想导致的,卡了我三天,花了整整三天看了我几十万行日志才debug出来这个问题……非常想死。
bug复现:
五台服务器0、1、2、3、4,存在各种可能性的网络分区,其中一种就是两个分区,一个两台一个三台。
2作为三台分区的Leader,可以正常进行共识,3作为两台分区的Leader,落后了很多很多log。
然后分区形势变了,2能和3连上了,这时候2会向3开始进行日志复制。
第一次rpc,3发现自己的log长度小于2发来的prevLogIndex,就返回了自己的长度XIndex=192,这时候2下一次rpc就会从3的最后一个log的index开始尝试复制日志。
第二次rpc,2把192和之后的log一起发过去,prevLogIndex和Term就应该取的191的,ok问题就出在这,191很不巧就是上一次Snapshot的index,也就是说getLog(191)会正好访问到那个物理坐标为0的dummy,而它的Term是0,所以在AppendEntries里面发现args.prevLogTerm == 0,好,直接当作心跳了,直接把191之前的都当成对的了。
这个bug在Lab2里面是测不出来的,又或者说可能全世界就我会写出这种bug…所以说不要像我这样用魔法数字来做一些边界测试,代码会越来越难维护,bug会越来越多
Bug-report - Lab3B错误的日志追赶
这一块我一直做的很差,做的很赶,很多细节都有问题。
如果使用了XLen XTerm这种参数形式的追赶方式,就不要再留着nextIndex[peer]–这种方式了,很容易导致被Snapshot卡住。导致完全没办法复制日志。任务直接超时120s的时限。
Comments